Switching (back) to Linux

As I very subtly (😅) hinted at back in the previous post, I have indeed switched to Linux this year. This March, to be more precise. And actually back to Linux, as I did use Linux as my daily OS in the early 2000s. In fact, I remember choosing a Radeon GPU when I got a new main PC in 2012 specifically for the better AMD Linux support compared to NVIDIA. (Which is the still case today. But we'll get to that!) Ironically I ended up not installing Linux on that machine after all, and stayed (relatively) happily with Windows 7 and finally Windows 10.
Anyway, I finally got myself a much needed upgrade: a new desktop PC last year — and even though I had at that point been using Linux Mint on an old Macbook Air over a year — I didn't anticipate switching from Windows on my main rig. And thus I ended up with a NVIDIA GPU.. 😛🤦♂️ The new PC has Windows 11; surely I'll eventually start to tolerate it, right? Right..? 🥲
Not quite! Due to the ever increasing enshittification of Windows, I had been growing more and more weary of it (and Microsofts antics in general), up to the point I decided to try an experiment:
Could I switch to Linux and still keep doing my work, personal projects — maybe even gaming? 🤔 Well, only one way to find out!
The Linux Experiment
So, in March I bought a new 2TB M.2 SSD, dropped it in and installed Linux. I'm still keeping the dual-boot with Windows 11 for the time being, as a backup. (Plus I still have my Lightroom photo collection on the Windows-side, have to look for a Linux-alternative at some point. Adobe in all their kindness terminated my perpetual Photoshop CS6-license 🙄, but so far they have left LS alone... But I digress.)
Despite some issues and annoyances, for the most part my experiment has been successful and quite refreshing! No more AI bullshit (Recall, Copilot — I mean what the hell!? 🤯), spying/privacy concerns or ads. No more forced Microsoft accounts & ninja-updates resetting my OS settings/adjustments! 🎉 I can choose. What to install, when to update, etc. What an outlandish concept: I am in charge of my PC and OS, not Microsoft — the way it should be. As I said: refreshing. Liberating.
I don't use Arch, btw. 😉 I did my fair share of distro-hopping back in 2002-2009 or so, and eventually settled on Debian and Ubuntu -based distros (after trying lots of things like Red Hat / Fedora, Slackware, SUSE and even Gentoo). With recent positive experiences using Mint on various older systems, that's what I went with for the main rig too. It's been fairly stable, and Cinnamon is nice if not the most modern looking of desktops. But it's well thought out and simple. The way updates are handled is 👌 (no nagging, no forced reboots). Still rocking the 6.8 kernel, so by default Mint is not ideal for very new hardware! 6.14 HWE is now available, though.
Anyway. I probably can't be bothered to distro-hop much, but I'd still like to check out KDE at some point, seems really pleasant these days. And I used to prefer Gnome 2 over KDE 2.x and 3.x (IIRC Plasma was 4.x and it was in rather rough shape back then). 🤔
Not perfect, but experiment will carry on...
After the switch, I got my personal projects (such as the movie collection -web app and the static site generator for this website) quickly running on Linux. Godot Engine naturally works well, did the AudioSplitter and related benchmarks 100% in Linux. Funnily enough: my sitegen — a .NET-app written in C# — works way faster in Linux! Generating this site takes a couple of seconds in Windows, and about 0.15 seconds in Linux. 😂 In fact Linux seems more efficient in general and uses much less RAM than Windows does in comparable scenarios. Which is nice.
Now Unity (Engine) on the other hand, for my day job.. The editor is usable but it has annoying quirks and feature omissions (such as setting the editor UI scale), so I do prefer the Windows-version. OpenGL rendering has occasional issues and Vulkan isn't perfect either (freezes Unity occasionally after waking up from suspend; might be NVIDIA related, too). At least with Unity 2022, haven't tried anything newer. Despite the annoyances I've kept on using the inferior version just because I enjoy time spent in Linux more. In fact, I reckon I've booted into Windows less than 10 times since March, and even then only to quickly check or adjust something. 🤷♂️
In general there have been some other issues here and there, for example I cannot read my fan RPM speeds in Linux due to Secure Boot (I guess I'll disable it should I fully get rid of Windows in the future). But nothing major and/or painful enough to make me go back to Windows.
UPDATE: One issue I forgot to mention; NVIDIA driver often prevents the PC from going to sleep (suspend), especially if I have Steam or Unity open. Annoying and hopefully gets fixed at some point. 😐

fastfetch-output! 😄 (Why yes, I have been playing DOOM lately, does it show..?)What about gaming?
Now I haven't really been gaming on PC in a long while (as evident by the now-mercifully-retired 2012 desktop 😅), but did get back into it last year with the new PC. As one does, in my experience. I picked a mid-tier GPU (NVIDIA RTX 4060 Ti OC 16 GB), but of course now that I have played more, should have picked a 4070.. Or a Radeon, rather, for Linux purposes. Maybe I'll switch some day.
One of the most interesting aspects of this "Linux experiment" has been testing gaming. These days — with Proton, DXVK, VKD3D and friends — the Linux gaming landscape is a bit different than what it was when I last used the OS. 🙂 I find it fascinating, that one can play Windows-only games on Linux with native-like performance (or sometimes even better, on AMD-based hardware!) with the D3D → Vulkan translation going on. Of course, not everything works and NVIDIA drivers take a big performance hit (15-30%, can be even bigger in DX12-games) compared to Windows, but still impressive. Who remembers the days of Tux Racer and only handful of other playable Linux 3D games? I do. Anti-cheat is another topic (although I'd say it's more of a developer/publisher issue than Linux-issue), but doesn't matter to me personally as I don't play any of those games.
Even with the infamous NVIDIA Linux-driver performance hit, I've been happily playing games, such as Kingdom Come: Deliverance, The Witcher 3, Dead Island 2, DOOM (2016) & Eternal. All but one of them worked great. Only Witcher 3 gave me some trouble with the ray-tracing DX12 perf. being especially bad (granted, I have 4060 Ti...) and freezing frequently. DX11 works much better. The new DOOM games use Vulkan and especially DOOM 2016 ran like a dream w/ settings maxed: rock solid 180 FPS (max on my monitor)! 🔥 Thus I enjoyed the game a whole lot more than I did first playing on PS4 back in 2017. 👍️ Shout-out to ProtonDB, a useful site for checking out Linux-compatibility on lots of games.
* * *
So, that's the current situation. I've spent 98% of my time in Linux since March, and even with some occasional issues, I don't expect to switch back to Windows any time soon. Perhaps if some must-have game I buy doesn't work at all, or some work-related emergency requires it, I'll have to boot into Windows, but so far it's not been the case.
I have casteth away the shackles of Windows once more and it feels good! ⛓️💪😬
If you have an older PC with Windows 10 fast approaching its end-of-life (and don't especially fancy updating to telemetry-ridden Windows 11), I do recommend checking out Linux as an alternative.
Anybody else fed up with Windows-bullshit, AI or otherwise? Tell me in the comments! Feel free to scold me on my questionable GPU choice, too! 😄 And — as always — thank you for reading this far!
Using Godot Engine for app development
 For last few years I've been following the Godot Engine development with great interest — especially after the infamous Unity Runtime Fee -fiasco (🤦♂️). About a year ago I started evaluating the Godot Engine, first by reading the documentation and then by making a simple game. Just to get a feel for the engine. I also began prototyping a game that might be worth pursuing further (been occasionally working on it for short stints), but that remains to be seen.. 🤔 Nonetheless I've documented my first Godot impressions (Gist): feel free to take a look, if interested.
For last few years I've been following the Godot Engine development with great interest — especially after the infamous Unity Runtime Fee -fiasco (🤦♂️). About a year ago I started evaluating the Godot Engine, first by reading the documentation and then by making a simple game. Just to get a feel for the engine. I also began prototyping a game that might be worth pursuing further (been occasionally working on it for short stints), but that remains to be seen.. 🤔 Nonetheless I've documented my first Godot impressions (Gist): feel free to take a look, if interested.
In any case, an opportunity presented itself to do further development with Godot on my day job. But instead of a game, I made a tool application! 🛠️ In this post I wanted to share my perspective on using Godot as an app framework. (With some performance benchmarks thrown in for good measure!)
Some background: at work we occasionally need to split long audio recordings of various items (words, usually, sometimes longer spoken parts) into separate files, with some processing performed and the output files properly named. All of this automated as much as possible. We had an old custom Python 2.x app for that; it did the job, but was somewhat cumbersome to use: very slow and flickery in rendering the audio waveform, zooming, making selections etc. Especially with huge audio files. I maintained and improved the app over the years, but didn't touch on the core issues (that would've required a rewrite anyway).
Which is exactly what I ended up doing! 😅 With Godot Engine 4.4 adding runtime WAV-loading I thought it'd be a perfect opportunity to try the Godot UI tooling and also do a better version of the audio splitting app for work. Two birds with one stone, as they say.
Enter the (aptly-named, if I may say so myself 😄)...
AudioSplitter

I started building the tool with GDScript to allow for rapid prototyping — hot-reloading script changes is a huge time-saver. First up was AudioView, the custom UI component (or Node, in Godot-terminology) responsible for rendering the audio waveform in efficient manner. With smaller audio files this was fine, but pretty soon I hit a performance ceiling with GDScript. The actual rendering of the lines was not the problem, but "down-sampling" (i.e. for each vertical line computing the relevant range in audio samples1 and finding the min-max values) the audio data for rendering was just too slow to be usable. Now I knew beforehand that GDScript is not the most performant language for raw number crunching like this, but it was still interesting to try. And as I said, for rapid prototyping and less number-crunchy stuff it's very nice!
What to do, then? With frame times of hundreds of milliseconds a smooth user experience would be impossible, even when only rendering as needed! 🤔 What's neat with Godot is that you can mix and match languages. I took my AudioView and ported it to C# AudioViewCS. This resulted in a huge speed increase, even better than what I had anticipated! 🔥 Impressed with speed-up I wrote a quick benchmarking rig to properly measure them, just for fun. See my benchmark2 results below:
| AudioView | Audio length | Render time avg. (ms) | Total (ms) | Difference |
|---|---|---|---|---|
| GDScript | ~5 min | 139.87 | 34 687.61 | 1x |
| C# | ~5 min | 1.73 | 427.91 | 81x |
| GDScript | ~36 min | 292.13 | 72 449.30 | 1x |
| C# | ~36 min | 4.26 | 1055.51 | 69x |
| AudioView | Audio length | Render time avg. (ms) | Total (ms) | Difference |
|---|---|---|---|---|
| GDScript | ~5 min | 278.14 | 69 676.25 | 1x |
| C# | ~5 min | 3.07 | 762.03 | 91x |
| GDScript | ~36 min | 440.07 | 110 215.92 | 1x |
| C# | ~36 min | 5.85 | 1450.11 | 75x |
NOTE: Audio view was fully zoomed out with 5 min clip, and only partially on 36 min clip. This explains how in the larger file the performance difference is smaller. Should've rendered the full waveform in hindsight, but hey, a quick benchmark is quick! 😛
 Pretty impressive gains, in my opinion! 👍️ Naturally, the bigger the audio view width, the larger the speed difference. Now that the C#-version runs so much better, the GDScript-variant is useless? Nope, I kept it around for a while after that whilst I was improving the rendering, adding the timeline markers etc. Hot-reload FTW, baby! 😬💪 (It is gone in the final product, though.)
Pretty impressive gains, in my opinion! 👍️ Naturally, the bigger the audio view width, the larger the speed difference. Now that the C#-version runs so much better, the GDScript-variant is useless? Nope, I kept it around for a while after that whilst I was improving the rendering, adding the timeline markers etc. Hot-reload FTW, baby! 😬💪 (It is gone in the final product, though.)
And no: I didn't convert any other parts of the app to C#, because I do like GDScript (with as much of static typing as possible!), and it worked fine and fast enough for the audio analysis, other UI code etc. GitLab reports 78.7% of GDScript code, and 18.8% of C#. Rest is shell scripts.
Just wanted to mention: this benchmark isn't meant to diss GDScript at all, but instead highlight the possibility of using other tools for the job (like C#, or even C++). It is great indeed that you can replace individual components with different tech if performance problems emerge! 🙂
* * *
 With the big performance issue nicely solved, I had quite a lot of fun implementing the rest of the interface using Godot UI nodes. Overlaid on top of the main
With the big performance issue nicely solved, I had quite a lot of fun implementing the rest of the interface using Godot UI nodes. Overlaid on top of the main AudioViewCS-node I have another custom node, that implements the selections manipulation & allows manually slicing the audio. Both of them share one scroll-bar. And that's it for custom components, the rest is built-in nodes. Rendering the custom components (inheriting Control) was enjoyable, just override _draw() and draw away!
After spending some time with them I do prefer Godots UI nodes over Unity UI components (disclaimer: I mean UGUI, I have not used the newer UI Elements). Layout nodes are very flexible in Godot and there are lots of useful nodes (spin boxes, text fields / editors were needed in this app) that have no counterpart in Unity UGUI. Not surprising, of course, as Godot editor itself uses the same UI components. For the most part I used the default theme with some tweaking, and also made a semi-shitty icon for the app.
There was one more thing I wanted to try. When AudioSplitter was fully working, I wanted to improve the UX by doing the audio loading, analysis and normalization in a separate background worker thread, to avoid freezing the app during those operations. Godot Engine threading support was a breeze to use: I got my worker thread up and running in no time at all. It uses the basic job queue -pattern: main thread constructs a Job-object with relevant data + a callback, posts it to the worker thread, which then picks it up, processes the job and posts back the results using the given callback. GDScript Callables were useful here.
All in all I was very impressed by how well Godot is suited for application development (despite being, you know, a game engine). Can't stress enough how useful the hot-reloading of scripts and syncing object properties is when building a UI! ✨
Nothing is perfect, though, and I did have some minor niggles: a peculiar bug with text fields + some editor crashes when updating my UI sub-scenes and switching back to main scene, while the app was running. Also the size of an exported .NET build is rather large: to combat that, I wrote a post-build script that removes most of the .NET DLLs and libraries that my sole C#-node doesn't need. Was able to save ~45 MB doing that. More space savings could be achieved by compiling the engine and leaving out unneeded stuff, but I didn't bother with that for an internal tool. Positives far outweigh the negatives and I'm definitely using Godot again for my future tool app needs! And likely games, too.
And that's that, for now. If you made it this far: thanks for reading, and feel free to comment! 🙂
-
For example: 30 minutes of mono PCM audio at 44.1 kHz sample rate has ~79 million samples.↩
-
Benchmarked on Ryzen 7 7700X PC in Linux build, with warm-up period. Rendered 250 frames of audio waveform (fully zoomed out with 5 min clip, partially on 36 min clip), discarded 1% slowest frame times.
(Hmm, Linux, you say? Do I sense another blog-post looming in the horizon..? 👀)↩
Movie collecting 2.1 (update!)
Ever since I resumed my movie collecting hobby, I've been occasionally improving the Movie collection -app I made. The movie collection itself has also grown considerably, perhaps worryingly so... 😅 Read on to find out more!
At the end of last year, I implemented a simple tagging system where each movie can be given tags. Those tags can be searched for, and I'm mainly using them to categorize my boutique label purchases. With the tags I can easily see my entire collection of, say, Arrow Video releases. I also use tags to mark some distinct release features like a slipcover or steelbook. Previously I was (ab)using the description field for these kind of things, but the tags make it much more convenient. And nicer, with those nifty colors! 🙂

The tags are hidden behind the tag-symbol on the main listing by default, and can be opened with a click. Clicking on a tag will show all movies tagged with it.
Tags could also be used to do genre categories, — I intentionally don't have a genre field stored for the movies — but I don't see myself needing the genre information anyway. And if I did, I'd add it as a field and do some IMDb-lookups and assign them automatically. Genre information might come in handy for statistics purposes, though.

Speaking of statistics: I've also revamped the Collection statistics-page with much nicer card-based layout and more of interesting (well, to me anyway!) stats. New stats include:
- Monthly purchases / watches per year: shows the monthly sums for both purchases and movie watches in color-coded blocks, divided into yearly buckets. Starting from 2022, because that's when I resumed the hobby and started tracking these again.
- Looking at the picture below, I must admit, these numbers do scare me slightly! I knew I bought a few movies last year, but was not expecting this... 😱💸
- I was meaning to add monthly costs to those blocks, but didn't quite find the courage to do it, yet. Perhaps the costs could be hidden by default, hmm.. 🤔
- Most watched movies (TOP 30), Foreign Regions and Duplicates: tabbed listings of the TOP 30 most watched titles, releases of foreign regions (non-European region locked discs) and duplicates (mainly releases in different formats).
- TV-series: titles that are TV-series (season releases or the whole series) are marked as such and excluded from most of the stats. E.g. separate TV-seasons will skew the production year counts, running time averages etc., so I've left them out from calculations.
* * *


In addition to the above, I've also improved the backend code: cleaner TypeScript, switch from CommonJS modules to ESM, more robust data scraping for the EAN-barcode scanning and better automatic backups. Among other tweaks. I'm also making more steps towards client side rendering; for example the tags are fully handled in client side with the backend only supplying the tags JSON.
* * *
PS. A tiny bit of absolutely useless trivia: this blog post was authored in Markdown instead of typing in HTML. I improved my trusty old static site generator to support .md-input files. Not that you can see the difference in the final output, but it does make typing these posts slightly nicer for me. You just gotta take my word for it! 😄 (Shout-out to Markdig / .NET Markdown processor — bolted that onto my generator and with trivial amount of additional work I was good to go. Nice!)
Movie collecting 2.0
Long time no see! 👋 (Has it really been over 5 years? Damn! 😲)
This post is about movies. In the recent years I've been getting back into my movie collecting (as physical media, that is) hobby and started watching movies a lot more once again. Fun times. But it quickly started to annoy me that I had no up-to-date list of my movies; while I did have a software for this exact purpose, I had been neglecting updating the collection and stopped altogether around 05/2010 (hmm... surely this isn't related to our first child being born...!? 🤔😅). While the software was alright, the workflow was too cumbersome: edit the collection on my home PC, export a CSV-file, upload it to a web server. Annoying. Especially with an increasing backlog of additions. All this meant that effectively the collection was about 12 years out of date. Not good!
I started thinking: wouldn't it be convenient to have a web app for managing the movie collection? That way I'd always have up-to-date list in my pocket, and when buying new discs I could easily check if I already had the movie (or had it in DVD while buying a Blu-ray upgrade — I've accidentally bought my fair share of duplicates from bargain bins! 🤦♂️). And crucially the process of adding new titles would be as simple as it gets: I could do it on my phone, without any extra export/upload steps. As a bonus, it'd be cool to have a barcode scanner to help with the workflow!
So with all that in mind, back in May 2022 I got to work, on my spare time. A few weeks later I ended up with a usable web application I've been occasionally improving. The app has been in use almost daily, as I've been watching a lot of movies and keep track of the watch dates*. I still want to improve the visuals a bit, but the app is feature-complete for my purposes already. The actual process of getting the collection up-to-date was of course a huge amount of work (importing the old collection data, combing over my shelves for movies that I had sold/upgraded, adding data the previous software didn't have, combing over the shelves again for new additions since 2010, trying to find their purchase information, dates, etc.), but it was so worth it. Should have done this years ago! 😎
 movies I've watched lately..")
Some notable features:
 Basic data stored per movie: title, director, release year, rating, purchase date, purchase price, disc format (now including 4K UHD), region codes, number of discs, running time, IMDb-link, optional description text and last watched dates (with full watch history).
Basic data stored per movie: title, director, release year, rating, purchase date, purchase price, disc format (now including 4K UHD), region codes, number of discs, running time, IMDb-link, optional description text and last watched dates (with full watch history).- EAN/UPC barcode scanning when adding new movies: uses the device camera and does a web-scrape with the barcode, trying to find out basic information. This has been really helpful when adding movies! (This library does the scanning part.)
- Responsive design: works on phones, tablets and desktops.
- Collection statistics -page: some stats across the whole collection, including histograms for ratings and production years. Also calculates the total cost of the collection (ouch! 😱💸).
- Automatic data export backups: weekly exports in
JSONandCSV-formats, zipped and emailed to me.

* * *
 Now some technical details, for those interested. 🤓 In the spirit of the previous movie collection software written as an exercise in Python/Qt (and its even earlier predecessor in C#), this project would function as a dive in the current web development techniques: both frontend and backend. Full-stack, as they say! 😀 Initially I had the idea of building several prototypes in different tech stacks, but with limited time available ended up choosing not to do that and instead went on completing my one prototype. I chose Node.js (with TypeScript), Express + Pug running in Google App Engine as my backend and simply Bootstrap + custom JavaScript as the front. It's currently a regular, mostly server rendered web app with limited dynamic content loading on the client side, but perhaps at some point I'll switch to SPA-model (single page app). While that'd be nifty, this already works fine for my purposes. 🤔
Now some technical details, for those interested. 🤓 In the spirit of the previous movie collection software written as an exercise in Python/Qt (and its even earlier predecessor in C#), this project would function as a dive in the current web development techniques: both frontend and backend. Full-stack, as they say! 😀 Initially I had the idea of building several prototypes in different tech stacks, but with limited time available ended up choosing not to do that and instead went on completing my one prototype. I chose Node.js (with TypeScript), Express + Pug running in Google App Engine as my backend and simply Bootstrap + custom JavaScript as the front. It's currently a regular, mostly server rendered web app with limited dynamic content loading on the client side, but perhaps at some point I'll switch to SPA-model (single page app). While that'd be nifty, this already works fine for my purposes. 🤔
Another important aspect was that I wanted to build the app to be as cost-effective as possible. Choosing App Engine and Firestore as the database was partly because of the low costs, and partly because of my experience with the former. Firestore can actually function serverless, but I wanted to try the backend development so that didn't matter. As a realtime (another feature I don't need) NoSQL database it's not the most obvious nor best choice for this use-case, but works and is basically free for my usage. And free is nice!
Initially I was wary of JavaScript because traditionally I've been a fan of statically typed languages (although Python is quite nice), but TypeScript was actually a pleasant surprise! Not bad at all. While still not a fan, I must admit vanilla-JS has improved a lot since I last took a look at it. Back in the days when JS was only used to open annoying pop-up windows and messages, and maybe change link images on hover events (CSS didn't exist yet).. 😅
* * *
*) The reason for keeping track of watch dates is I have a top twenty list of most watched movies in the collection statistics page. At this point the list isn't very exciting, but it will be interesting to see in, say, 10 years (probably in time for another blog post or two, considering my current posting frequency!) what movies I have ended up watching the most. And I do re-watch stuff regularly.
Behind The Scenes: Oddhop Puzzles
It's been well over a year since our "glorious" Oddhop launch that — in the grand scheme of things — basically amounted to about two and half farts in the wind.. 😛 So, to celebrate our triumph I decided to let you guys and gals on a little secret: all of the puzzles in Oddhop are procedurally generated. 😎 That's right. We did hand-pick the puzzles, but we didn't come up with them in "traditional means" (whatever those may be for your average puzzle game): instead we created a tool for the puzzle generation.
Without further ado, let's get behind the scenes. This post is not going to be overly technical, but also hopefully not too trivial either. Let me know if it turned out to be worth reading. Oh, be sure to click on the pictures to actually see what's going on.
* * *

Game designer Teemu came up with the basic procedure of generating these "jump over piece to eliminate" puzzles, and that was the starting point for 1st prototype I did. It's interesting to note that the algorithm works backwards: it starts from the final, solved state of the puzzle and traces backwards from there. Essentially it starts with one piece on the board (the last remaining piece from players point of view), jumps it to a chosen direction, and spawns another piece to be eaten when playing the puzzle. Then a random piece is picked, and it is again moved and a new piece gets added. And so on.
While all that sounds very simple on paper, and was simple at the beginning of the prototype, it actually turned out not to be the case! Instead I got the fun but difficult programming challenge to make a generator that could create proper levels based on various features and parameters. So for each gameplay feature there was quite a bit of head-scratching in how I could fit that into the generator, creating levels that are actually solvable, and in way that didn't break the existing gameplay features already in! No point generating puzzles that cannot be solved, right? 🙂 Essentially each gameplay mechanic needed to be implemented twice: way to reliably generate them (difficult!) and way for the player to perform them in game (much easier!). If you ever were wondering why creating the game took over 2 years, I can tell you the puzzle generator was a big part of it.
Basically each level had a random seed and set of parameters (including version) that were used as an input to the generator. I added a textbox to the UI where the input was shown as a comma separated text string (V17,1193020924,10,1,1,1,0,0,1,0,1,0,0,0,1,0,1,0,0,0,0,0,2), so we could easily copy/paste levels and share them by email, in text form. (Actual level serialization was implemented late in the development cycle, not to mention sharing binary files wouldn't have been as quick and easy as sharing pieces of text.) So for example I would play with the generator, and when it yielded a nice level I'd take the input string and shared it with Teemu ("hey check out this cool level!") and vice versa. We often challenged each other to solve the puzzle, to see who did it with fewer tries. Teemu assembled the final level packs, and I contributed some levels (meaning I just randomly found nice puzzles! 😉). As you can see in the GIF above, gameplay is fully integrated into the generator, so levels can be immediately tested while searching for that "one nice puzzle".
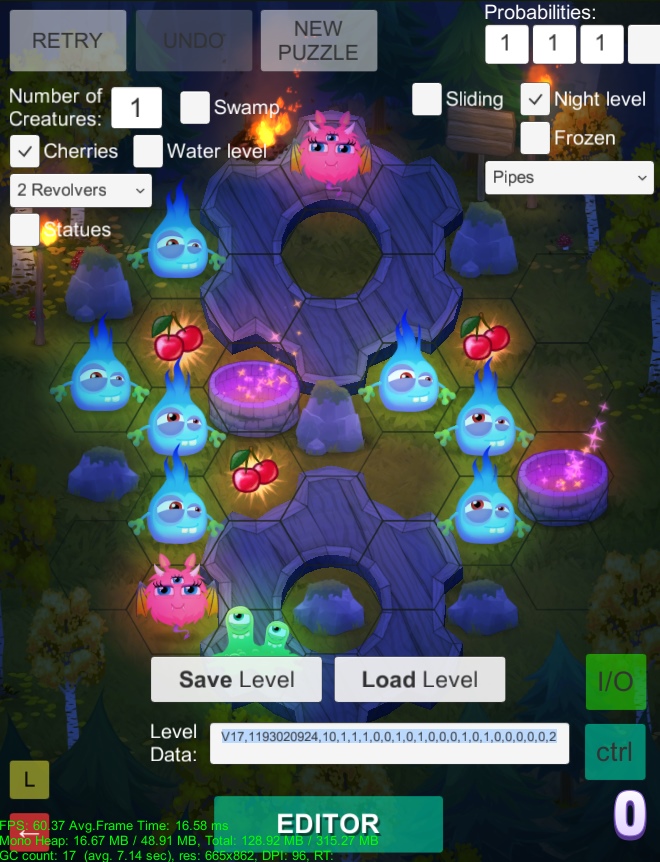


Like I mentioned, levels also had a version, which meant that the generator needed to backwards support several versions of levels. We kept iterating on the mechanics and tweaking the generation heuristics (more on those below) and obviously that often required lots of changes in the generator, and I tried to keep it all working, including the old level inputs we had gathered. In hindsight that was unnecessary complexity, as I don't think we used any of the old levels in the final game. 😐 Periodically I cleaned the code and took out support for very old, obsolete versions. I had a growing version specifier, and it got up to V17 meaning 17 iterations on the input format (actual generator changed much more, of course). When I finally implemented level pack serialization and we saved the levels, I could happily get rid of the remaining backwards compatibility from the code. And there was much rejoicing.
As the programmers among us can imagine, the generator code got very complex in the end and touching it for feature tweaks or anything was scary to say the least. Not to mention debugging the puzzle generation when a gameplay feature was yielding invalid (unsolvable) puzzles! 😵 I made a debug output that printed out each step (the level layout, that is) of the generation in textual format to the Unity console, so I could pinpoint the step where it went wrong and fix it. And for some puzzles I generated I couldn't solve them in reasonable time, assumed the generator was broken and examined the debug output only to find out it was actually solvable and I was just too stupid! 😄 I also gave some puzzles to my wife when I couldn't solve them, and either she solved it or I stumbled upon the solution watching her try. Or we gave up and checked the debug output.. Good times!

Some gameplay features were quite tricky compared to others: for example the sliding flowers / ice patches (they were actually oil stains initially!) and the portals/wells gave me some trouble to implement correctly. We also had to scrap some gameplay mechanics because they were deemed too difficult to implement into the generation, or were painstakingly implemented but were not fun or necessary. That was always painful! 😄 On the right you can see some pen & paper design I did for the lily pads generation; originally they were meant to always slide to the jump direction (like the flowers ended up doing). While that particular instance in the pic worked, I couldn't get the generation work reliably so we went with simpler implementation, although the sliding flowers did add some of that back.
Bonuses (the cherries) were randomly placed on cells that were visited by any creature during the generation, so that they could be actually collected. Likewise, obstacles (rocks) were placed on cells that had no visits. All the creatures start as normal blue monsters, and get "promoted" during the generation to their special roles. When searching for direction for a creature to move, the generator first checks if there are "half-baked" green two-headed blobs around, and prefers those. This is so that the green dudes actually get two jumps over, otherwise they could just as well be normal blues. Frozen creatures are internally realized as green slimes with secondary (player visible) type assigned, they spawn out "half-eaten" and when jumped over second time get frozen in place.
Some gameplay mechanics were incompatible with each other — or maybe you set some ridiculous parameters, amount of creatures etc. — so the generator tried to brute force a valid level out, but if it couldn't in 512 tries it stopped and displayed a warning that the level is likely invalid. And actually the generator always tried to generate 10 potential levels and pick the best one from the those. (The warning was displayed when it couldn't generate even one potential level.) To decide if any given level was a potential level, we had lots of heuristics in place to discard bad or boring levels. For example, if a creature that was frozen didn't get to move at all before being eaten (after being freed from the ice), the generator discarded the level and tried again. Or maybe we had revolving platforms but nobody ended up standing on them at puzzle start? Or a dude went through portal only to do nothing? That's boring, so the generator discarded these. For each potential level the generator took up to 512 tries to find a level candidate.
With the 10 potential levels, the generator picked the one with the most variance in creature starting positions, meaning the one that likely had most movement across the map. After all it'd be boring to have creatures moving in one corner for the whole level, right? I remember we were discussing that maybe we had too many heuristics in place, as the levels could get quite "uniform" in a way, and I added "less heuristics"-toggle to the editor. 😄 Can't remember if that was actually used at all, though. At least it doesn't appear the UI any more.. Maybe the heuristics were relaxed, or something.
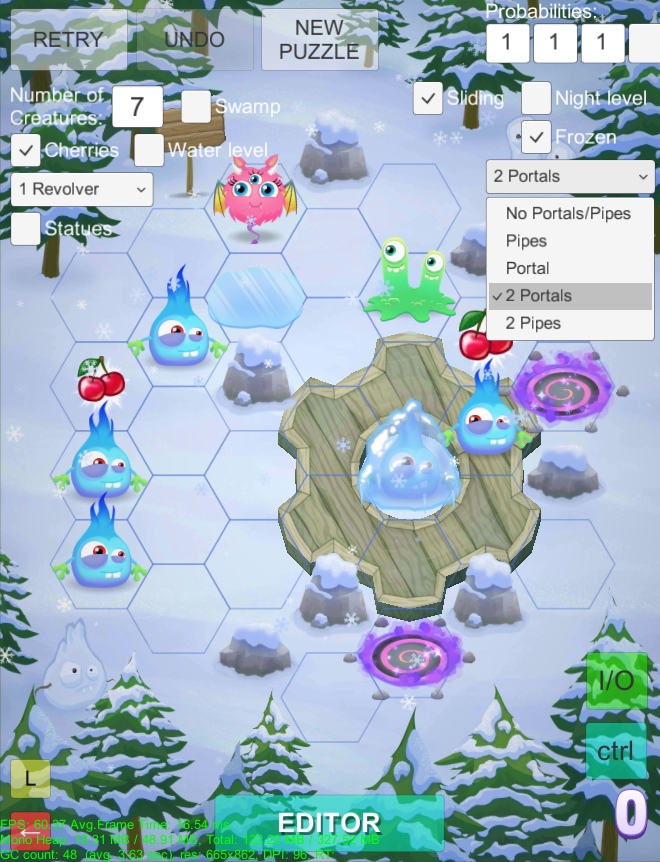

* * *
Remember I said that all of the puzzles were procedurally generated? I kinda lied, but only a bit: for a couple of the tutorial (intro) levels we did edit the generated puzzles. Ironically the need to edit levels in the end of the development cycle meant I had to make an editor that allowed moving/changing the creatures, cherries and obstacles. The editor was used to tweak the tutorial levels and also to do some visual adjustments to the random obstacle generation for many non-tutorial levels. The actual gameplay content in Oddhop is still exclusively work done by the puzzle generator, we just picked out the best bits. 🙂 After over two years of service, the level generation code was unceremoniously stripped out of the release builds, as it wasn't needed at runtime because the level packs were serialized into binary format.
Additionally, if you're wondering why to bother with the fancy generator at all: two reasons. First, it seemed like a neat idea to program a thingy to generate the puzzles (naturally that turned out to be a huge pain point during the project due to its eventual complexity! 😛). And second: I had plans to actually make a more polished UI for it and include it in the game build for the players to use. So they could create endless levels to play, and perhaps share good puzzles with other players. Perhaps even Puzzle of the week -type of things etc. Unfortunately the game didn't catch on so there was no point in doing that, and also no reason to implement the new gameplay mechanics we had designed, but not yet bolted on to the generator.. 🙁
Anyway, I hope this has been half interesting read. Have a good day, and do comment if you want to ask on the subject or enjoyed the post! 🙂
 Follow @mhgames.org
Follow @mhgames.org Follow @mhgames_
Follow @mhgames_
